skiplist 又称跳跃表,是一个数据节构,可以实现红黑树类似的功能,插入或删除元素后保持有序。插入和删除的复杂度都是O(log n)。
skiplist 除了具有红黑树的功能外,还能支持从下标取元素的操作(类似skipList[10]这样的访问)。
skiplist 基于概率均衡,不保证平衡性(但通常效果都不错)。它相对于传统的平衡树优势在于原理更简单,代码实现上更简洁高效。
原理
跳跃表可以看作是传统单链表的扩展。有序的单链表插入和删除的复杂度都是O(n)的。
跳跃表对有序单链表的每个节点进行了扩展。在每个节点原来有一个指向下一节点的指针的基础上,新增一系列指针,让第二个指针指向当前节点往后数第2个节点,第三个指针指向当前节点住后数第4个节点…以此类推,第n个指针指向当前点后的第$2^{n-1}$个节点。如下图如示。实际实现时,是基于随机算法,步长不是完全精确的为$2^{n-1}$。
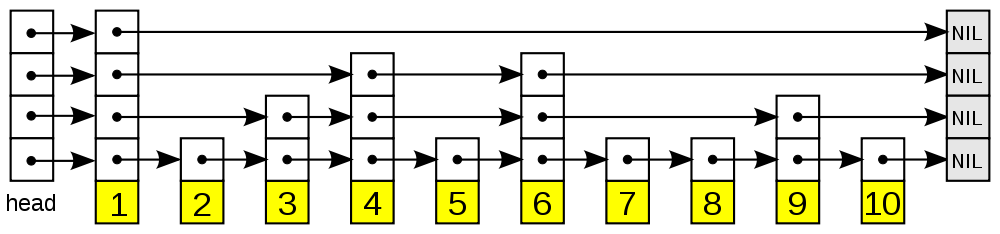
这样一来,插入、删除或者查找节点时,从上往下,先用上层的指针确定范围,再往下一层,减小步长,继续查找,缩小范围,直到确定位置。
通过对单链表扩展,新增一系列步长指数增长的指针,跳跃表插入、删除、查找的复杂度优化到了O(log n)。
实现
接下来看看跳跃表的 java 实现。
数据结构
首先需要一个数据结构存储每个节点。
1
2
3
4
5
6
7
8
| private class Node<T> {
T element;
Integer score;
Node<T>[] backward;
Node<T>[] level;
int[] span = new int[MAX_LEVEL];
}
|
然后是整个跳跃表类。
1
2
3
4
5
6
7
| public class SkipList<E> {
final static int MAX_LEVEL = 32;
private Node<E> head;
private Node<E> tail;
public int level;
public int size;
}
|
查询
查询对应位置的元素
在维护好跳跃表的前提下,查询跳跃表中给定位置的元素是很容易的。
- 从 head 结点开始,level = MAX_LEVEL - 1 开始遍历
- 如果跳到 next[level] 后超出查询的下标,level 减1,节点的下标由遍历时前驱的 span 之和计算得来;
- 否则跳到 next[level] 节点;
- 重复2,3步,直到level=-1.
1
2
3
4
5
6
7
8
9
10
11
| public Node<E> findEntry(int index) {
Node<E>entry = head;
for (int i = MAX_LEVEL - 1; i >= 0; --i) {
while (entry.level[i] != null && entry.span[i] <= index) { index -= entry.span[i]; entry = entry.level[i]; } } return entry; } ``` ### 查询某个区间顺序所有元素 先利用上一步结果,查到 startIdx 对应的结点,然后从该点开始遍历即可。 ``` public Set<Pair<E, Integer>> range(int startIdx, int endIdx) {
TreeSet<Pair<E, Integer>> result = new TreeSet<Pair<E, Integer>>(pairComparator);
Node<E>node = this.findEntry(startIdx);
for (int idx = startIdx; idx < endIdx + 1 && node != null && node != tail; ++idx, node = node.level[0]) {
result.add(new Pair<E, Integer>(node.element, node.score));
}
return result;
}
|
查询某个元素的下标
和第一步查询下标对应的元素类似,上面是把 index 减到0,这边让 index 从0开始加,直到跳到链表中与要查询元素值一样的时候结束。最后得到的 index 便是需要的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| private int getIndex(Node<E>node) {
int index = 0;
Node<E>entry = head;
for (int i = Math.min(level, MAX_LEVEL - 1); i >= 0; --i) {
while (entry.level[i] != null && entry.level[i].compareTo(node) <= 0) { index += entry.span[i]; entry = entry.level[i]; } assert entry.compareTo(node) <= 0; } return index; } ``` ## 插入元素 插入元素时,先利用前面的方法查找到需要插入的位置前插入,更新level 0的前驱后继关系。 ```java public boolean add(E element, int score) { Node<E>node = new Node<E>(element, score);
Node<E>entry = findEntry(element, score);
if (entry.compareTo(node) == 0 || (entry.level[0] != null && entry.level[0].compareTo(node) == 0)) {
return true;
}
node.span[0] = 1;
size += 1;
Node<E>next = entry.level[0];
if (next != null) {
next.backward[0] = node;
}
node.backward[0] = entry;
node.level[0] = next;
entry.level[0] = node;
updateSpanAdd(node);
return true;
}
|
插入元素后更新 span
如果只是插入更新 level 0 指针,这样就退化成简单的双向链表了。我们还需要结新加入的结点随机赋予高度,并更新 span 值。
更新 span 的主要思想是,新加入节点在 level i 的 span 值为在 level i 的前驱(backward[i])的 span 值减去新节点同前驱的 index 之差。与此同时,更新前驱的 span 值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| public void updateSpanAdd(Node<E> node) {
Node<E>entry = head;
int randomLevel = 0;
for (int i = 0; i < level; ++i) {
if (Math.random() > 0.5) {
randomLevel++;
}
}
if (randomLevel == level && level < MAX_LEVEL - 1) {
++level;
head.span[level] = size;
head.level[level] = tail;
tail.backward[level] = head;
}
int nodeIndex = this.getIndex(node);
int index = 0;
entry = head;
for (int i = Math.min(level, MAX_LEVEL - 1); i >= 1; --i) {
while (entry.level[i] != null && entry.level[i].compareTo(node) < 0) {
index += entry.span[i];
entry = entry.level[i];
}
assert entry.compareTo(node) < 0;
if (entry.span[i] != 0 && i > 0) entry.span[i] += 1;
if (i <= randomLevel) { node.span[i] = entry.span[i] - (nodeIndex - index); node.level[i] = entry.level[i]; entry.level[i] = node; entry.span[i] = nodeIndex - index; node.backward[i] = entry; Node<E>next = node.level[i];
if (next != null) {
next.backward[i] = node;
}
}
}
}
|
删除元素
删除前更新 span
与插入操作不同,删除元素时需要先更新 span,对要删除结点所有 level 上的前驱,对应的 span 减1。
1
2
3
4
5
6
| public void updateSpanRemove(Node<E> node) {
Node<E>entry = head;
for (int i = Math.min(level, MAX_LEVEL - 1); i >= 1; --i) {
while (entry.level[i] != null && entry.level[i].compareTo(node) <= 0) { entry = entry.level[i]; } if (entry.span[i] != 0 && i> 0) entry.span[i] -= 1;
}
}
|
从跳跃表中删除元素
查找到要删除元素的位置,从链接中删除。更新每个 level 上的前驱后继关系和前驱的 span 值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public boolean remove(E element, int score) {
Node<E>node = new Node<E>(element, score);
this.updateSpanRemove(node);
Node<E>entry = findEntry(element, score);
if (entry.compareTo(node) < 0 && entry.level[0] != null) entry = entry.level[0];
if (entry.compareTo(node) != 0) return false;
for (int i = level; i >= 0; --i) {
Node<E>prev = entry.backward[i];
Node<E>next = entry.level[i];
if (prev != null) {
prev.level[i] = next;
if (i > 0) prev.span[i] += entry.span[i];
}
if (next != null) {
next.backward[i] = prev;
}
}
--size;
return true;
}
|